Viral Spread Theory in RKnot¶
RKnot is built up from the contact level. A contact is an interaction between an infected person and a susceptible person that could result in transmission of the virus (more details below). Contacts occur in a 2d environment in which subjects move randomly according to pre-defined distributions or deterministically according to event subscription.
When a contact occurs, transmission is determined stochastically according to a multi-faceted likelihood of transmission tailored specifically to the infected and susceptible subjects in contact at the specific time at the specific location.
The expected number of new infections at any time, can be found as the sum of all contacts at that time multiplied each contact’s specific transmission risk.
\(\tau\) is a fundamental property of virus that can be further augmented for properties of the infected, or the subject, or the location of the contact.
Thus, the transmission risk of the virus is required in order to mimick its spread. This can be provided directly or derived from a virus’ estimated \(R_0\).
\(R_0\)¶
The propensity for a virus to spread is most-commonly referenced by its Basic Reproduction Number, \(R_0\). \(R_0\) is the number of new infections that will be caused by a single infected person in an entirely susceptible population.
At an individual level, \(R_0\) is influenced by many factors: the number of contacts the infected person has, the location of contacts, the social setting of contacts, etc.
At a population level, many models of \(R_0\) assume that the individual factors average out, thus leaving us with a property that is fundamental to the virus itself. We can see there is a broad range of \(R_0\) values for different viruses in the wikipedia entry.
\(R_0\) can be described as:
The above ignores the number of contacts made, however, \(\beta\) can be further broken down as:
which yields:
Using the relationship above, we can simulate viral spread contact by contact, however, we must have a value(s) for \(\tau\).
Static Transmission Risk¶
There are many mathematical models used to describe viral transmission, the most commonly-referenced being the SIR model (Suscepitble-Infected-Recovered).
The SIR model makes several simplifying assumptions:
- Closed, well-mixed population with no demography
- Constant Rates
This allows viral spread to be described in 3 equations.
The simplified model allows for some quick estimates of various spread characteristics. Herd Immunity threshold, for instance, can be found as:
For instance, \(R_0\) of 2.5x, the prevailing estimate for sars-cov-2, yields a HIT of 60%.
The assumption of constant rates presents problems for simulating at the contact level, however. SIR assumes that transmission risk is constant during the infection period and that each subject in the population has the same number of contacts and so is able to ignore \(\tau\) and \(c\).
Referring to equation (5) above:
- \(R_0\) is known (from external analysis and provided by the user)
- \(d\) is known (from external analysis and provided by the user)
Thus, unknowns are \(\tau\) & \(\overline{c}\)
As per above, we must know \(\tau\) in order to simulate spread.
Expected Contact Rate¶
While we do not know \(\overline{c}\), the simulation space is given a number of parameters that allow us to estimate the expected number of contacts. We know:
- The population size
- The number of locations
- The movement patterns of subjects
- The likelihood that a subject will be at a particular location at a particular time given 1/2/3 above
A simple method to estimate \(\overline{c}\) is to assume that each subject is equally likely to be in any one location at any time. The probability of a single dot being in a singe location is:
The probability of another dot being there at the same time:
The probability of \(k\) dots being at the same location at the same time:
Then, the number of ordered contacts is:
And for all possible orders:
In fact, we can prove that the contact rate for an equal mover is the density using probability theory. We can view the probability of contact with other dots in the space as a binomial random variable with the trials representing the number of dots at a location, so:
If there are three dots (and 3 locations), the distribution governing their interactions is the sum of the two Binomial functions:
We know the sum of two Binomial distributions is:
so:
and for k dots:
which simplifies to:
and we know the mean of a binomial distribution is the product \(n*p\)
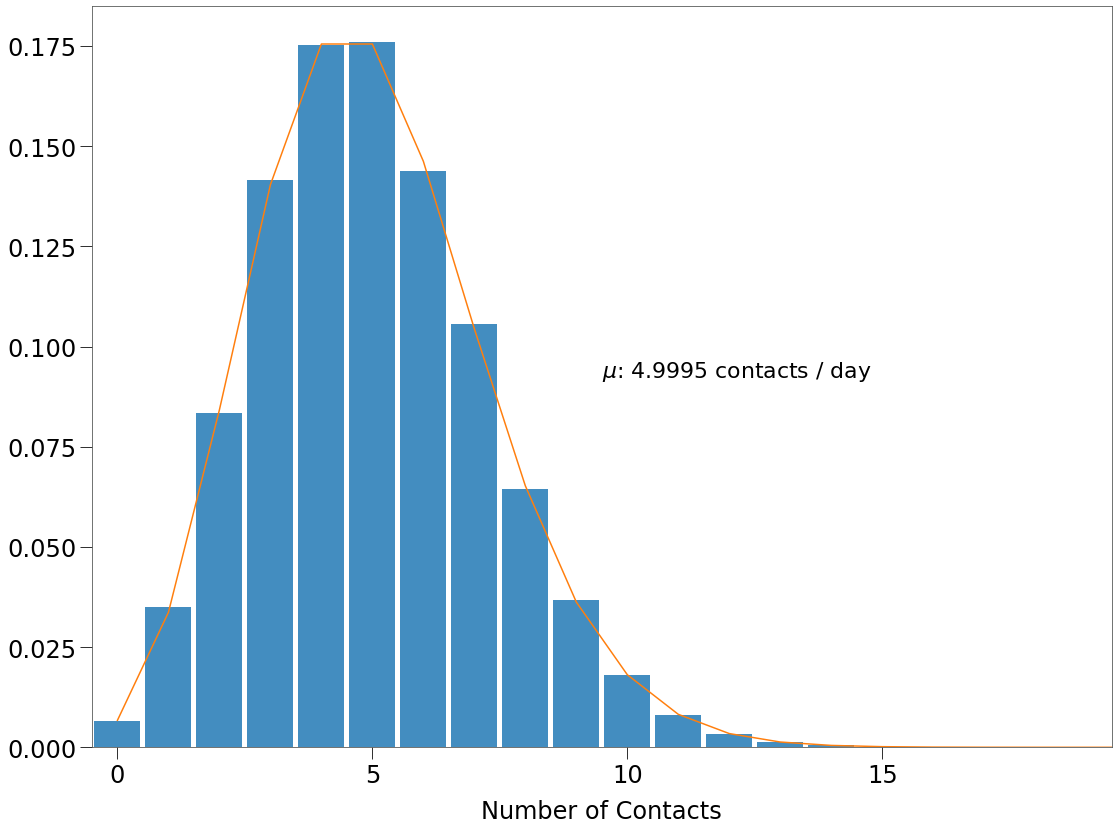
We can see that relationship below, where an environment with density of 5 generates a \(\overline{k}\) of 5.
[85]:
import numpy as np
import scipy.stats as st
import matplotlib.pyplot as plt
density = 5
n_dots = 10000
n_locs = n_dots // density
# binom always returns n + 1
p = 1 / n_locs
n = n_dots - 1
x = np.arange(n + 1)
kontact = st.binom(n, p)
fig, ax = plt.subplots(1,1, figsize=(16,12))
counts, bins, _ = plt.hist(
np.random.binomial(n, p, 100000),
bins=x, density=True, rwidth=.9
)
ax.plot(x+.5, kontact.pmf(x))
ax.set_xticks([i+.5 for i in range(20) if not i % 5])
ax.set_xticklabels([i for i in range(20) if not i % 5])
ax.set_xlabel('Number of Contacts')
plt.text(.5, .5, f'$\mu$: {n*p} contacts / day', transform=ax.transAxes)
plt.xlim(0,20)
plt.gcf().set_facecolor('white') # Or any color
plt.tight_layout()
plt.savefig('imgs/binom.png')
Likelihood of Transmission¶
With the expected contact rate known, probability of transmission under the SIR model is found as:
So, again, If a susceptible subject has contact with an infected at the same location, at any time, its probability of infection is:
If a susceptible comes in contact with multiple infected, we assume that this results in multiple contacts that occur in succession. So we must sum all the branches of the probability tree that end in an infection:
This ensures that the likelihood of transmission is asymptotic to 1, as follows:

Dynamic Transmission Risk¶
The SIR model makes several assumptions that make for simpler math, but that do not map well onto reality.
In particular, SIR assumes constant transmission risk,
, when in reality, we know that the infectiousness of an individual changes over time as a function of viral load. It takes time for the virus to accumulate in the subject and, then, in turn it takes time for the subject to dimish the virus via its immune response.
Generally, the greater the viral load, the greater the transmission risk. And so the likelihood of transmission should follow a similar pattern as the viral load (or vice versa). This New York Times piece has a nice visualisation of this concept for sar-cov-2.
There are several techinques available for incorporating viral load in a viral spread model including serial interval, explored here and generation time, explored here. These techniques, however, again tend to ignore \(\overline{c}\) and focus on \(\beta\).
Hutch Model¶
A paper from a team at the Fred Hutchinson Cancer Research Center, however, maps transmission risk directly onto an estimated viral load curve and infectiousness factor and optimizes it at a specfic contact rate and contact variance (hence forth known as the Hutch model).
First, we will show how the dynamic transmission risk curve is derived. The goal is to produce an array of non-zero probabilites reflecting the likelihood of transmission of virus from one infected to a susceptible in a single contact, based on the known viral load characteristics of the virus.
The Fred model combines quantities of infectiousness and viral load. Viral load is found via a system of 6 differential equations as follows:
The variable v is the viral load.
With viral load known, the transmission risk, \(\tau\), can be found as:
The paper provides estimates for several of the parameters including \(\gamma\), \(\alpha\), etc. The system can be described and solved using the odeint method in scipy.
[65]:
import math
import numpy as np
from scipy.integrate import odeint
def inf_rate(beta,v,s):
return beta*v*s
def sfunc(beta, v, s):
return -inf_rate(beta, v, s)
def vfunc(pi,i,c,v):
return pi*i - c*v
def ifunc(beta, v, s, delta, i, k, m, e, r, phi):
inf_r = inf_rate(beta,v,s)
dens_rate = delta*(i**k)
acq_res = (m * e**r) / (e**r + phi**r)
return inf_r - dens_rate*i - acq_res*i
def m1func(omega, i, m1, q):
return omega*i*m1 - q*m1
def m2func(q, m1, m2):
return q * (m1-m2)
def efunc(q, m2, dE, e):
return q*m2 - dE*e
def model(z,t):
beta=10**-7.23
k=0.08
delta= 3.13
pi=10**2.59
m=3.21
omega=10**-4.55
r=10
dE=1
q=2.4*10**-5
c=15
s, i, v, m1, m2, e = z[0], z[1], z[2], z[3], z[4], z[5]
dsdt = sfunc(beta, v, s)
didt = ifunc(beta, v, s, delta, i, k, m, e, r, phi)
dvdt = vfunc(pi,i,c,v)
dm1dt = m1func(omega, i, m1, q)
dm2dt = m2func(q, m1, m2)
dedt = efunc(q, m2, dE, e)
dzdt = [dsdt,didt,dvdt,dm1dt,dm2dt,dedt]
return dzdt
# FROM PRIOR RESEARCH
pi=10**2.59
c = 15
S0=10**7
I0=1
V0=pi*I0/c
M10=1
M20=0
E0=0
phi=100
z0 = [S0, I0, V0, M10, M20, E0]
t = np.linspace(0,20,30*4)
z = odeint(model,z0,t)
v= z[:, 2]
This results in the curve below, which shows the level of virus present in an infected person over time.
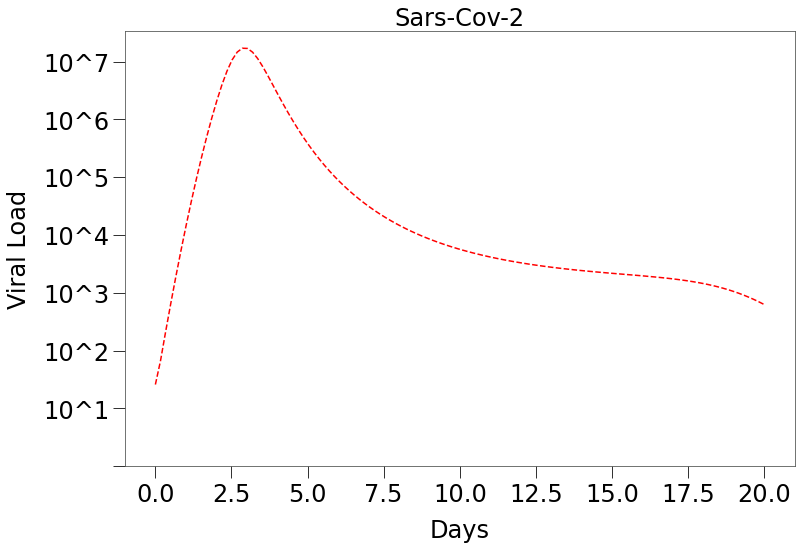
We can see that sars-cov-2 viral load can have a long tail, however, the Hutch paper showed that the amount of virus present during the tail is unlikely to result in high transmission, as per below.
Transmission risk is derived from the viral load above as well as two properties of the infectiousness of the subjects in the contact, \(\alpha\) and \(\gamma\) (see the paper for more details).
The paper estimated \(\alpha\) = 0.8 and \(\gamma\) = \(10^7\).
[67]:
def infness(v, alpha, gamma):
num = v**alpha
den = gamma**alpha + v**alpha
return num/den
def taufunc(v, alpha, gamma):
return infness(v, alpha, gamma)**2
alpha = 0.8
gamma = 10**7
vlin = np.linspace(1, 10**10, 10**5)
tmr = taufunc(vlin, alpha, gamma)
tmr is the transmission risk curve that we will utilize in our simulations. It is a 1d array with each element representing the likelihood of transmission of the virus at that point in the infection’s life cycle.
We can see from the plot below, that transmission risk only increases materially at exponentially higher viral loads:
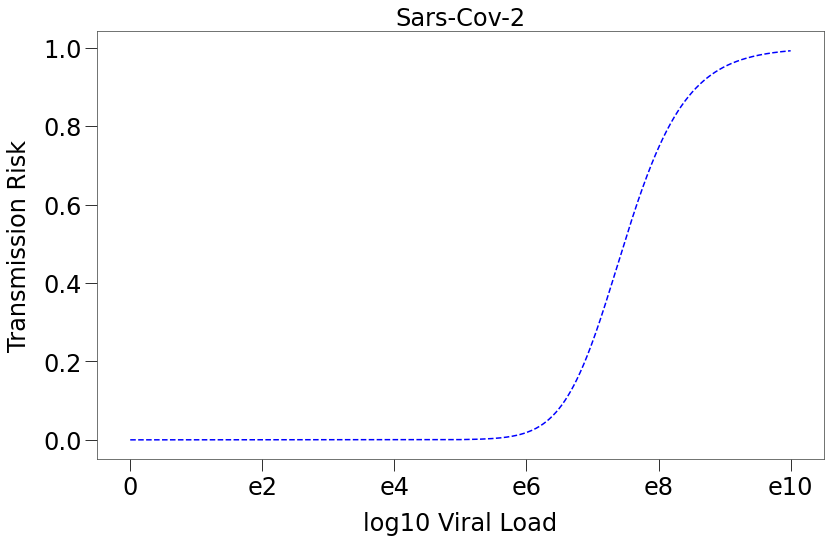
We can further combine Chart 1 and Chart 2 above to show that transmission of sars-cov-2 is likely only during a very narrow range in the early stage of infection.
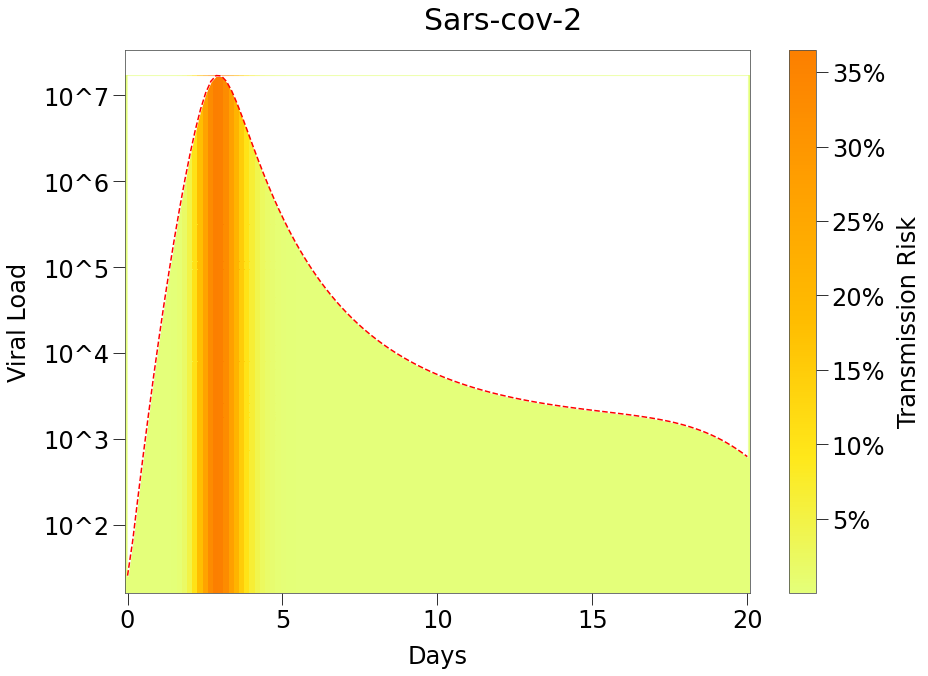
Note that there is only a significant risk of transmission of the virus for during the first few days of the infection period (shown as the more orange color under the curve).
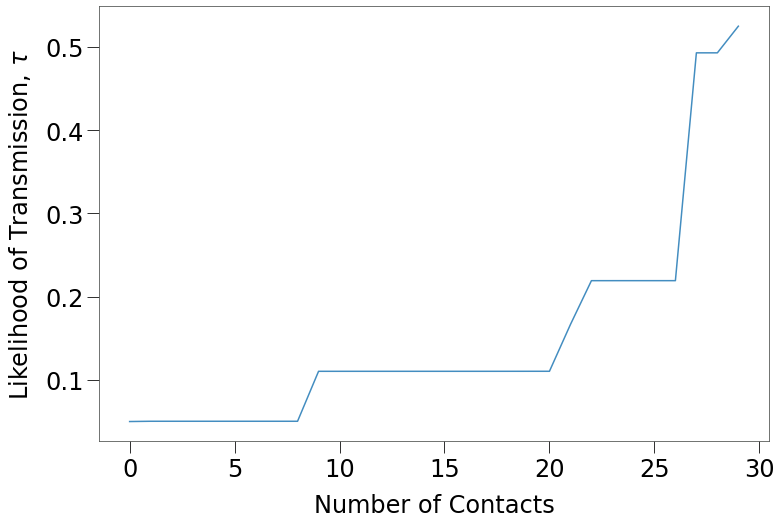
If we assume random \(\tau\) values from tmr curve above for 30 different infected dots, the likelihood of transmission to a susceptible as a function of the number of dots at the same location, scales as follows:
Other Forms of Heterogeneity¶
RKnot seeks to address the shortfalls in \(R_0\) models by allowing the user to introduce customized, heterogeneous populations across several axis including:
- Fatality Rate
- Population Density
- Movement - frequency and distance of location changes in space according to different probability distributions.
- Events - in the real world, people do not move and interact according to smooth probability functions. In fact, they typically have a small subset of movements that are huge outliers from any distribution. These are the professional sporting events, vacation trips, church functions, house parties, etc. that are scheduled and often times recurring. Thankfully, they are more often than not deterministic, which allows us to incorporate them in a simulation.
- Susceptibility - segments of population can be made immune (without requiring vaccination) to mimick phenomenon like possible T-cell immunity.
- Subject Transmission Factor, \(T_i\): \(R_0\) assumes that all contacts have the same transmission risk, \(\tau\) (subject to the viral load at the time of the interaction). RKnot introduces a unitless Transmission Factor, \(T\), for each subject at each contact that can modulate \(\tau\). This can be used to mimick social distancing or mask wearing or different socio-cultural norms that may impact spread (i.e. east Asian bows versus southern European double-kisses).
Still To Be Incorporated
- Location Transmission Factor, \(T_{\text{xy}}\): similar to \(T_i\) above, we can introduce a transmission factor to specific locations that might result in higher or lower likelihood of spread. This could be used to simulate certain work environments (like enclosed office spaces or meat-packing plants). It can also be used to mimic seasonality, by changing \(T_{xy}\) over time to account for, say, more time outdoors in temperate seasons.
- Testing and Isolation - with the heightened awareness of a pandemic, individuals in population are more likely to self-isolate or quarantine themselves upon sympton onset, thereby helping to reduce spread.
The Average Contact¶
Currently, RKnot assumes that each and every contact is an Average Contact.
The average contact is a purely theoretical interaction that would result in about an average likelihood of transmission relative to all other possible interactions. It is not influenced by external factors such as the demographics of the subjects, the properties of the location, etc. Thus, the \(\tau\) of an Average Contact is a fundamental property of the virus.
I like to think of the Average Contact as the Elevator Case, i.e.:
- Two people on an elevator, standing three feet apart, having a conversation for several minutes before one person exits. No masks nor other conscious social distancing, but no particularly reckless behaviour either.
Every other conceivable interaction can now be scaled relative to the Elevator Case on a continuum of higher or lower probability of transmission using transmission factors, \(T\). For instance:
- two college students pressed closely together on a concert floor and yelling at the band on stage would have \(T >>> 1x\)
- two people standing in a open field, 6 feet apart with masks on exchanging limited pleasantries would have \(T <<< 1x\)
References¶
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3782273/
- https://www.bmj.com/content/370/bmj.m3563
- https://www.medrxiv.org/content/10.1101/2020.06.28.20142190v1
- https://fivethirtyeight.com/features/without-a-vaccine-herd-immunity-wont-save-us/
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3935673/
- https://web.stanford.edu/~jhj1/teachingdocs/Jones-on-R0.pdf
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1804098/
- https://www.ijidonline.com/article/S1201-9712%2820%2930119-3/pdf
- https://www.nytimes.com/interactive/2020/10/02/science/charting-a-coronavirus-infection.html?s=03
- https://www.ijidonline.com/article/S1201-9712%2820%2930119-3/pdf
- https://www.medrxiv.org/content/10.1101/2020.03.08.20032946v1.full.pdf